在這 30 天中,跟著我的腳步一起踏進機器學習的世界,前半段我會帶著大家從機器學習最最最基礎的概念開始了解,了解到基本概念後,後半段就會開始進行 Pytorch 模型的實作與 Django 網頁的結合,想必對機器學習或深度學習具有熱沈的你一定非常興奮吧,那事不宜遲我們就開始吧 ! Let’s Gooo ~
機器學習是 AI 人工智慧與電腦科學 ( Computer Science ) 的一個分支,其專注於演算法 ( Algorithms ) 與資料 ( Data ) 的使用,為了就是讓模型去模仿人類學習的方式,在這當中不斷地改善準確度,機器學習在各個領域中都有著廣泛的應用,如:
若我們要知道甚麼是香蕉,就要先看過香蕉長甚麼樣子,這樣別人拿香蕉給我看時我才能分辨出來,而機器學習也是如此,不斷地把香蕉圖片 ( 資料 ) 給模型看,模型就會不斷調整辨識結果的準確度,最後便能夠準確分辨出香蕉,這就是模型的訓練目的,如果我今天拿很多不同種類的狗和貓圖片給模型看,那模型就會在訓練的過程中學習到能夠辨識出貓狗的方法,因此訓練完後我拿一張瑪爾濟斯的圖片輸入到模型,模型就會用學到的方法來辨識出這是一隻狗,而在機器學習中讓模型去學習的方法有很多種,通常會根據不同的問題或任務 ( Task ) 主要分為五種學習方法:
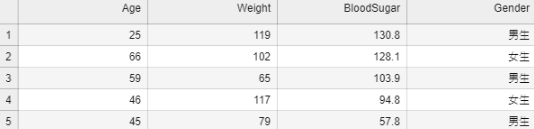
上面提到的兩個例子就屬於監督式學習,我們要讓模型能夠分辨出香蕉,就會讓模型先知道香蕉長甚麼樣子,就會給模型香蕉的圖片,而這些圖片就是所謂的標籤資料,有了標籤資料模型就能以這個標籤為目標去做更準確的分辨,監度式學習的主要概念就是,我要讓你分辨這個東西,我就要先讓你看過這個東西 ( 標籤 ),因此要用監督式學習來訓練模型時,通常都要準備許多的含有標籤的標籤資料 ( Labeled Data ),模型的輸出即是標籤,這些標籤資料就可用來讓模型知道輸入與輸出之間的關係,下面為 5 筆標籤資料,其 Diabetes 欄位的資料就是標籤,用來表示是否患有糖尿病,有為 1 無為 0,會做為模型的輸出,而前面四個欄位 ( 特徵資料 ) 會做為模型的輸入:

半監督式學習相對於監督式學習就不會給模型學習這麼多的含有標籤的資料,全部資料中有部分都沒有標籤,為無標籤資料 ( Unlabeled Data ),下面為 5 筆無標籤資料:
在許多的情況下,進行監督式學習需要準備很多的標籤資料,然而標籤資料相對於無標籤資料在獲取上可能較不容易,但用半監督式學習就不需要這麼多標籤資料,並且可用無標籤資料的特性去改善模型的效能,對學習更有幫助。
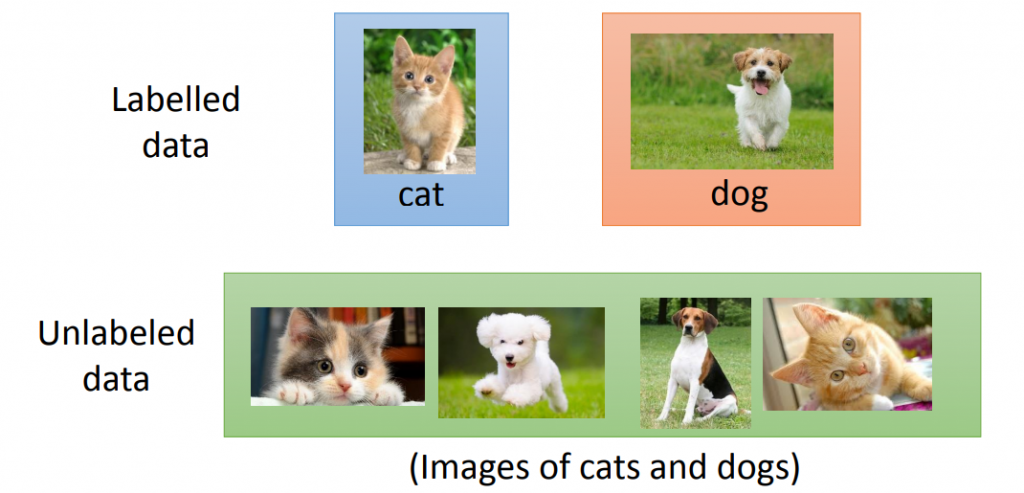
如果是監督式學習的話,給模型的資料都會在圖片上標記為 cat 或是 dog ( 如上圖 ),也就是標籤資料 ( Labeled data ),至於非監督式學習,在這個學習方法下給模型的資料都全是無標籤資料 ( Unlabeled data ),模型沒辦法知道標籤長怎樣,就像是給模型一張瑪爾濟斯的圖片要它分辨這是一隻 dog,因為無標籤資料 ( Unlabelled data ) 不會在圖片上標記出 cat 或是 dog,所以模型在訓練時就會不知道輸入的圖片要長得怎樣才算是dog,這時模型就要在這些無標籤資料中自己慢慢摸索出資料潛在的結構、規律或模式,在一次次的訓練中逐漸理解出正確辨認為 dog 的方法。
大家應該都有玩過 Google 的小恐龍吧,當初在在訓練小恐龍的過程中,應該是要告訴它面對到障礙物要如何反應,但在增強學習中,我們不會告訴它距離多遠要起跳,或是要跨越障礙物要怎麼做,全都要靠自己在錯誤中學習,會設定小恐龍只要撞到仙人掌或碰到其他的障礙物時就算失敗,遊戲就會結束重來,讓小恐龍在每次失敗中,計算出障礙物的長寬高、在距離障礙物多遠時起跳等,如果還是失敗就在重來一次,直到能夠計算出適當的距離,或是找到最佳的方法能夠成功跨越障礙物,這時候我們就會獎勵小恐龍,讓它知道這樣做是對的,它就會把正確的方法學起來,而如果失敗,就會懲罰小恐龍,它就會知道這樣做是錯,就不會學習這個方法,小恐龍就會在每次的成功與失敗中逐漸學習到跨越障礙物的方法,變得越來越強,以延長在遊戲中存活的時間,這種方式就叫做增強學習。
下面這段影片展現了如何透過增強學習讓 AI 學會走路,從不會走路到學會走路的整個過程。
https://www.youtube.com/watch?v=L_4BPjLBF4E&t=102s
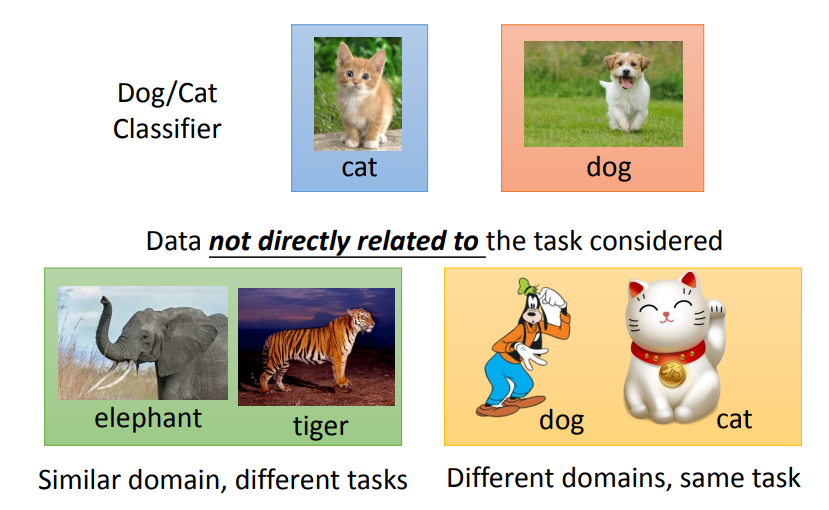
假設我們有以有個分辨貓狗模型 ( 分類器 ),而現在我們想要能夠分辨一個東西的模型,而這個東西和貓狗沒有直接相關性,所謂和貓狗沒有直接相關的圖片,可能是招財貓或者是高飛狗,而我們之前拿來分辨貓狗圖片的模型,對這個模型有沒有幫助呢,其實我們只要使用它經過訓練後所得到的模型參數,當作我們現在想要的模型的初始參數,就可以繼續接著訓練得出新的模型,已經事先用資料訓練好的模型為預訓練模型 ( Pre-trained Model ),於是我們就會使用預訓練模型的參數,然後套用在自己的模型中當作初始參數,就好像是從預訓練模型遷移到自己的模型一樣,然後再接著繼續訓練得到基於預訓練模型的最終模型,這就叫做遷移學習。
在今天我們學習到了:
在弄懂機器學習的框架後,在明天就要來介紹機器學習整體的流程,就能夠對模型的訓練更有概念,那我們下篇文章見 ~
https://www.youtube.com/watch?v=CXgbekl66jc&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49
https://medium.com/@yuhsienyeh/machine-learning-transfer-learning-遷移學習-5095f8a14367
https://www.youtube.com/watch?v=qD6iD4TFsdQ

